

In this article we’ll discuss a simple technique to drastically reduce the credit spend of a growing Snowflake project.
This is the first article in a series of posts dealing with cost optimization in Snowflake, the data cloud.
One of the most important differentiators in the platform is the ability to size processing clusters with just a click of the mouse. Often, new and starting teams start by building a one-node, extra-small-sized processing cluster and process any kind of data workload on that node.
After a while, typically both long and short-running queries will execute on that very same warehouse. Now take in mind the cost model. Snowflake bills by the second, though anytime a warehouse starts, it bills a minimum of one minute.
Let’s try to find a way to make sure that our queries run for a maximum of one minute.
Calculating the query length long tail
To have a first understanding of the query duration distribution per warehouse, we need to get to the data. In our demo setup, we have a warehouse in a place called LOAD. It is optimistically scaled as a medium warehouse and it consumes 4 credits an hour.
Historically, all of our workloads have been running on this LOAD warehouse, and our assumption is that we can split data loading workloads from transformation and analysis workloads. Let’s investigate this assumption and optimize our setup.
Snowflake exposes a number of statistics related to the inner workings of this warehouse through the shared SNOWFLAKE database. Find this information in the QUERY HISTORY table in the ACCOUNT USAGE schema.
To quickly analyze the information in this table, we’ll use the Snowsight interface for Snowflake. It comes by default with any Snowflake deployment but is hidden in plain sight under the preview app button

This analyst interface to Snowflake allows us to execute queries and visualize the results right away.
This query will build buckets of a with of 1 second which we can use to build our longtail histogram
SELECT
FLOOR(EXECUTION_TIME/1000.00)*1000 AS BIN_FLOOR,
COUNT(EXECUTION_TIME) AS COUNT
FROM “SNOWFLAKE”.”ACCOUNT_USAGE”.”QUERY_HISTORY”
WHERE WAREHOUSE_NAME = ‘LOAD’
GROUP BY 1;
Visualize the results immediately by selecting the Chart button in the middle of the screen
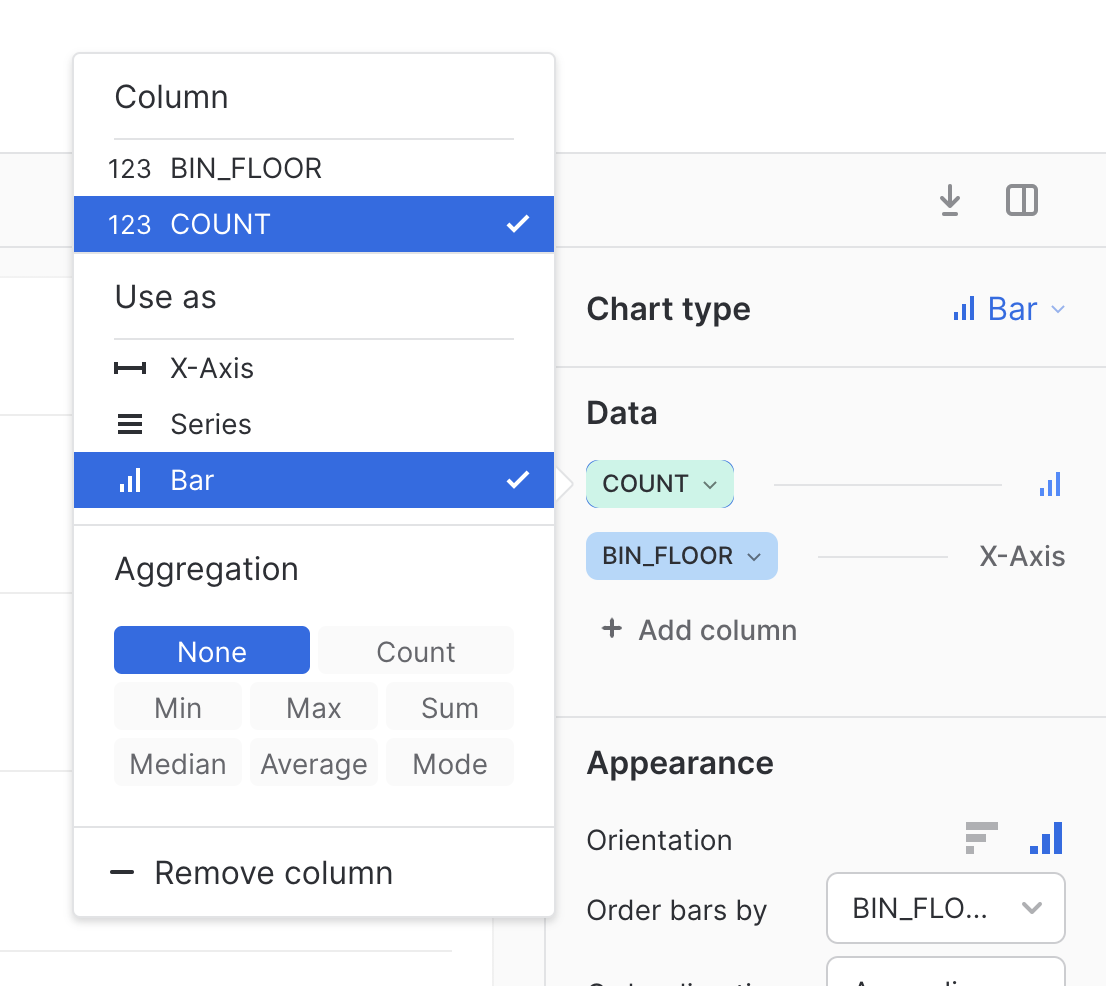
By default, Snowsight will use an extra layer of aggregation in their graphs that will distort the output of our analysis here. So let’s make sure to set that to none.
Finally, we get to the histogram that shows us how long queries take. The gray bar is the cutoff line for the one-minute minimum charge.
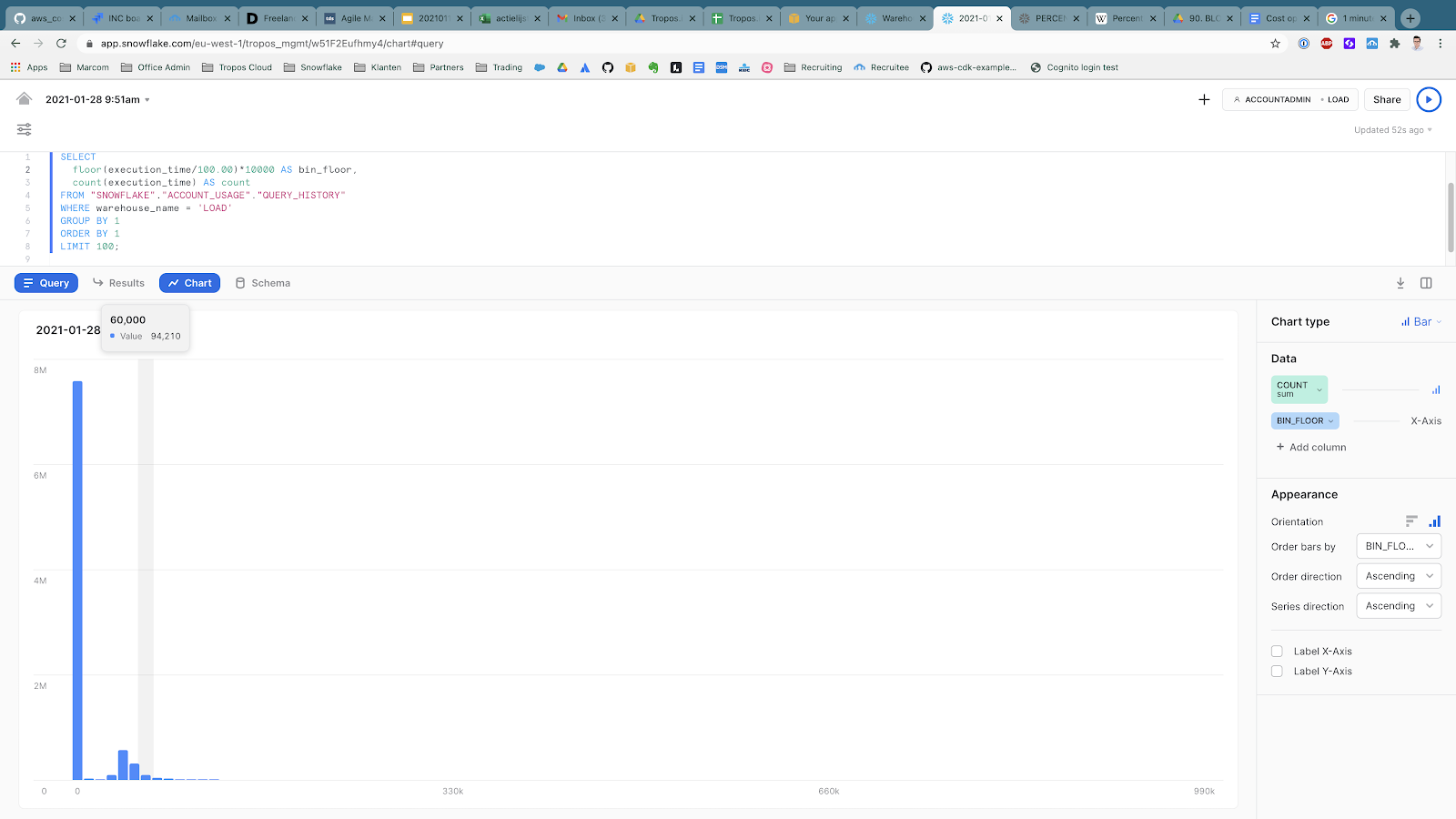
It turns out that the majority of queries run blazing fast (thanks, Snowflake!) and we have considerable opportunities to optimize
The action
Intuitively we have 2 actions to take:
- Downscale the current instance to an XS. It’ll about quadruple the processing time of the fastest queries but that will still be within the minimum charge of one minute
- Shift the workloads that require faster processing to a new warehouse
Action one is fairly straightforward and can be done using one simple query
ALTER WAREHOUSE “LOAD” SET WAREHOUSE_SIZE = ‘XSMALL’ AUTO_SUSPEND = 60;
Action two takes a bit more planning.
We start by isolating the queries that require more processing power. This particular Snowflake instance doesn’t apply query tags, so we need to investigate the actual queries that take over half a minute to process.
SELECT QUERY_TEXT, EXECUTION_TIME FROM “SNOWFLAKE”.”ACCOUNT_USAGE”.”QUERY_HISTORY”
WHERE EXECUTION_TIME > 30000
ORDER BY EXECUTION_TIME DESC;
Now, we need a warehouse to host those queries. Let’s create a new medium warehouse named NEW_WAREHOUSE by running this query:
CREATE WAREHOUSE NEW_WAREHOUSE WITH WAREHOUSE_SIZE = ‘MEDIUM’ WAREHOUSE_TYPE = ‘STANDARD’ AUTO_SUSPEND = 300 AUTO_RESUME = TRUE;
Analyze the queries that are reported back. Change the clients that execute those queries, and point those clients to the new warehouse we’ve just created.
Conclusion
Far fewer queries will use the new warehouse so it’ll be started less. The queries executed on the original warehouse will take a slightly bit more time to execute, but they will stay well within the one-minute minimum Snowflake charge.
The method proposed in this article is quite a simplification of reality, though often with a material impact on cost. Multiple queries can run at the same time, and a query run on a warehouse that is already active doesn’t call for another one-minute minimum charge. A more advanced method of cost management would take more parameters into account, such as parallel processing capabilities and warehouse sizes.





