

In this series, I focus on the critical differences between Snowflake and BigQuery that impact the data pipeline, table design, performance, and costs. Hence, it is by no means a detailed product comparison or benchmark.
- Part 1: virtual warehouses, data storage and data loading/unloading
- Part 2: data sharing and multi-cloud capabilities
- Part 3: unstructured data, data masking & data security features and SQL support
Account hierarchy
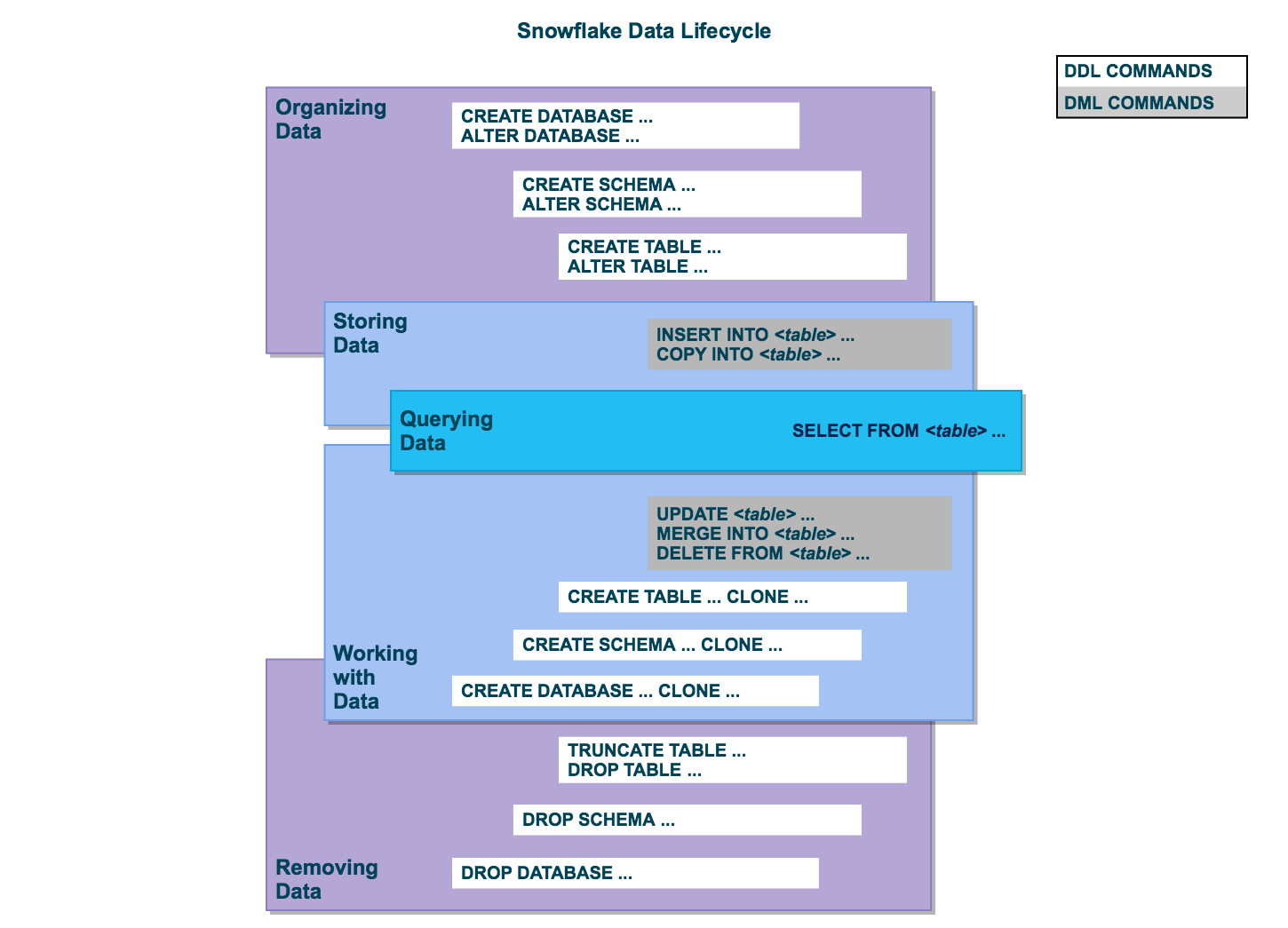
The way data is organized very similarly.
In a Snowflake environment, you create one or more Snowflake accounts. A Snowflake account is located in 1 of the major cloud providers (AWS/Azure/GCP) in a particular region.
A Snowflake account is a container for one or more databases with more schemas containing tables views… This is very similar to OLTP databases. A Snowflake organization sits above all the Snowflake accounts.
BigQuery on GCP is a fully managed service that integrated seamlessly in the GCP resource hierarchy in your GCP account.
As soon as the Google BigQuery API has been enabled for your project and granted BigQuery roles and permissions in Cloud IAM, you can create one or more BigQuery datasets. A dataset is located in a multi-region, for example, the EU or a more specific region. BigQuery hasn’t got the concept of schemas.
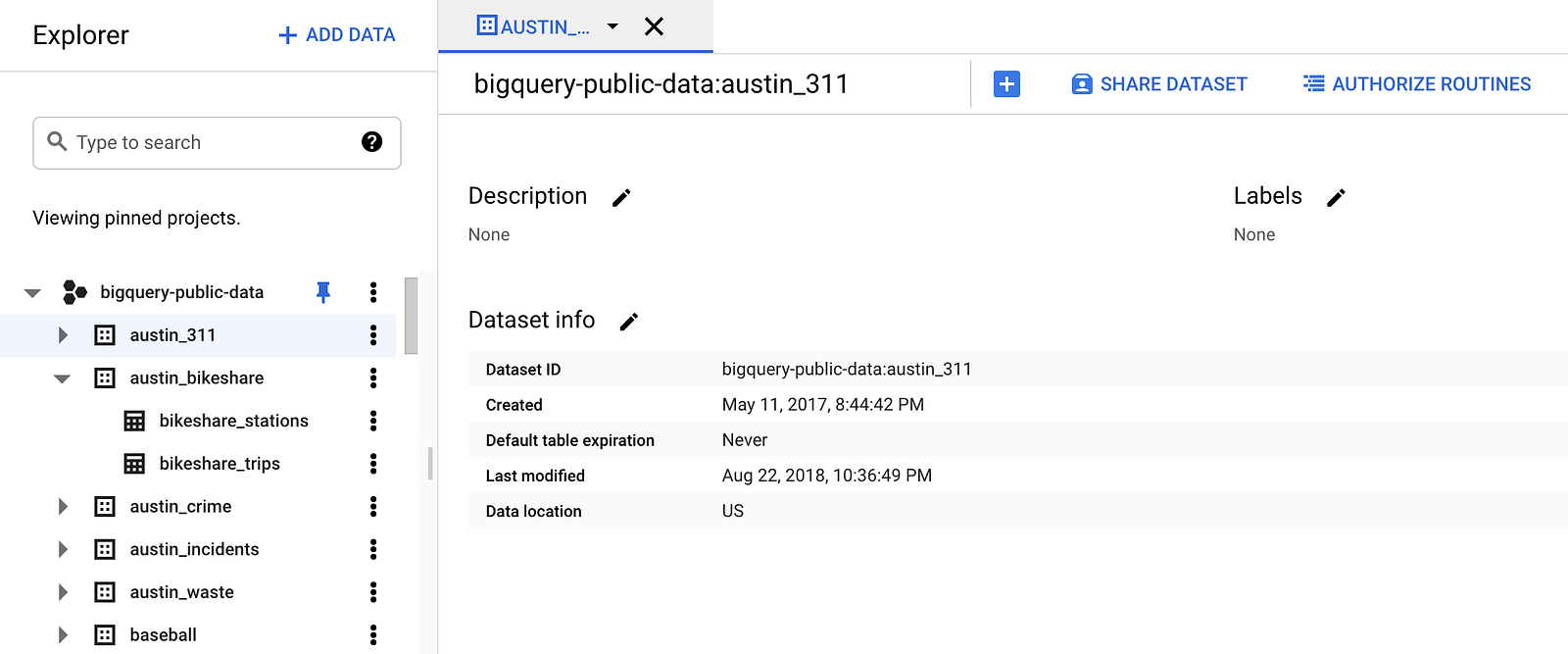
Having multiple datasets in different regions in a project in BigQuery can be an advantage. Still, it can be a bit tricky because you need to run the BigQuery jobs, aka queries, from the same region. Furthermore, in the EU, it’s very likely a policy will be in place that data can only be located in the EU multi-region or EU regions.
Data federation & multi-cloud data sharing capabilities
BigQuery can access data in Google Storage buckets, MySQL, and Postgres data if these databases are running in CloudSQL and BigTable, a Google-managed Hbase compatible wide-column store. Reading from CloudSQL and BigTable is a powerful feature because it’s possible to write a large part of the data pipeline in SQL.
Google Cloud IAM and BigQuery are global services, so it’s possible to grant access, full access or read-only, to datasets or specific tables/views to Cloud Identities outside of your organization. This can be prevented by configuring a policy. It is recommended to use authorized views to limit access to the underlying tables.
The data storage costs are billed to the project the datasets belong to. The query costs will be billed to the project that queries the data.
Since mid-2020, Google Omni has been in preview; this brings a managed version of the BigQuery query engine to Azure and AWS, so the data doesn’t need to move to GCP. Public pricing and detailed features are not yet available.
Recently Google announced several upcoming new services, such as Dataplex and Analytics Hub, with additional data sharing and monitoring capabilities.
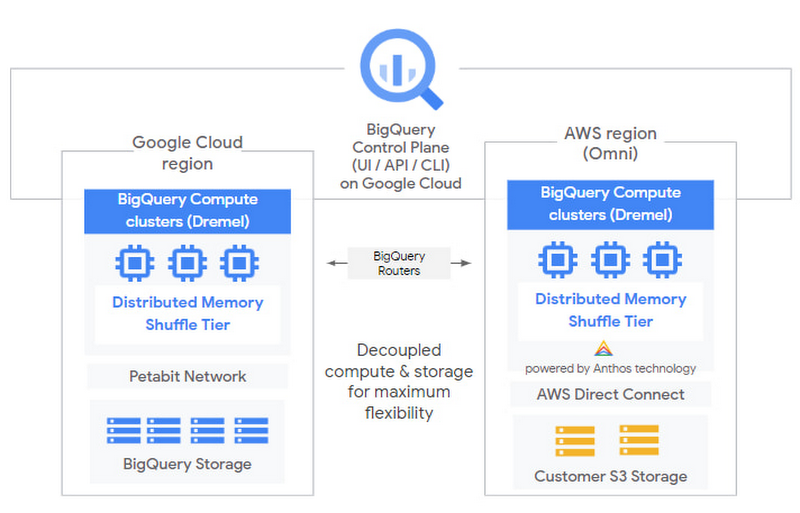
Snowflake’s platform has been natively designed with multi-cloud and data sharing in mind, and this clearly shows as soon as you go into the details.
Data needs to be pushed to Snowflake using internal or external stages.
A stage is Snowflake terminology for a distributed storage bucket. The difference with BigQuery is that a Snowflake account can load/unload data, and create external tables, on external stages located in Azure/AWS or GCP. The IAM of the cloud provider handles the access to external stages, so fine-grained control and customer-managed encryption are available.
This functionality enables many application scenarios because large companies use multiple cloud platforms. Hence, accessing data from other internal departments or external parties in other clouds with more minor error-prone data movements is a game-changer.

Secure data sharing is another core functionality of Snowflake.
An account admin, or anybody with the proper permissions, can act as a data provider and share tables, secured views, and secured functions.
Then it’s up to the data consumer to configure the share, so the data appears as a read-only database. If you want to buy or monetize data, this can be done as a secure direct share via a configurable data exchange portal or the public Snowflake data marketplace. Data sharing leverages the cloud metadata layer to grant access to the data in storage, so no data is copied.
If the data needs to be shared cross-region or cross-cloud provider, it’s only a matter of configuring automatic data replication.
The data providers cover data storage costs, data consumption, warehouse credits, and billed to the data consumer. Reader accounts can be created to provide access to other parties that don’t have a Snowflake account.

The secure data sharing capabilities of the Snowflake, The Data Cloud, enables plenty of internal and external use-cases.
In the actual “data mesh” fashion, domains can offer fully documented, up-to-date, and governed data products to other internal and external domains or stakeholders.

Data Cloning
In BigQuery, it’s possible to use CREATE TABLE AS SELECT … to copy data into a new table quickly.
In Snowflake’s platform, this is possible, but often a better alternative is “zero-copy cloning.” Instead of duplicating the data, the Snowflake metadata will point to the existing micro-partitions.
Further updates to the cloned data will generate new micro-partitions.
In the end, cloning is faster and less costly because less data is stored and needs to be manipulated.
This is powerful functionality if you need to create development environments or quickly troubleshoot or fix data without any impact on the base tables. Depending on what you clone, the database/schema or table, grants are by default not copied. Hence, it’s also easy to mask the data in development environments by specifying the most appropriate masking policy.
Conclusion
From a data sharing point of view, Snowflake is a proven Data Cloud available on three major cloud providers with automatic global scale secure data sharing.
Google BigQuery, and other competitors, are closing the gaps by introducing multi-cloud capabilities and data transfer services to keep distributed storage and tables in sync between regions and clouds. It is less automatic than Snowflake’s platform’s data sharing and cloning capabilities.
The Snowflake and BigQuery data marketplace growth and the number of data shares mentioned in the latest Snowflake summit indicate that specific industries are ready to embrace this. Image a world without fragile data pipelines that do barely more than copying stale data between distributed storage accounts or even worse…SFTP servers 😃
This will free up resources in data teams to focus on helping the business to generate more business value instead of spending a large chunk of the budget on only moving data around. Easier ways to offer data monetization at scale will be a new opportunity for industries.
In the next and last blog post of this series, we will look into how BigQuery and Snowflake handle semi-structured data, data security, and SQL.
Get in touch if you have any questions or suggestions! At Tropos.io, as a Snowflake partner, we can help your team design a cost-efficient, secure, and flexible data pipeline.






