

I joined Tropos.io to focus on data in the cloud with a modern data stack.
For the last 3 years, I’ve been working in Google Cloud environments with BigQuery as the main tool for data lake, data engineering, data warehousing and data sharing workloads. At Tropos.io, depending on the requirements, these workloads are often developed using Snowflake The Data Cloud on the cloud platform selected by the customer.
In this series, I’m focussing on the key differences between Snowflake and BigQuery that have an impact on the data pipeline, table design, performance and costs so it is by no means a detailed product comparison or benchmark.
- Part 1: compute, data storage and data loading/unloading
- Part 2: data sharing and multi-cloud capabilities
- Part 3: unstructured data, data masking & data security features and SQL support
Data storage & compute
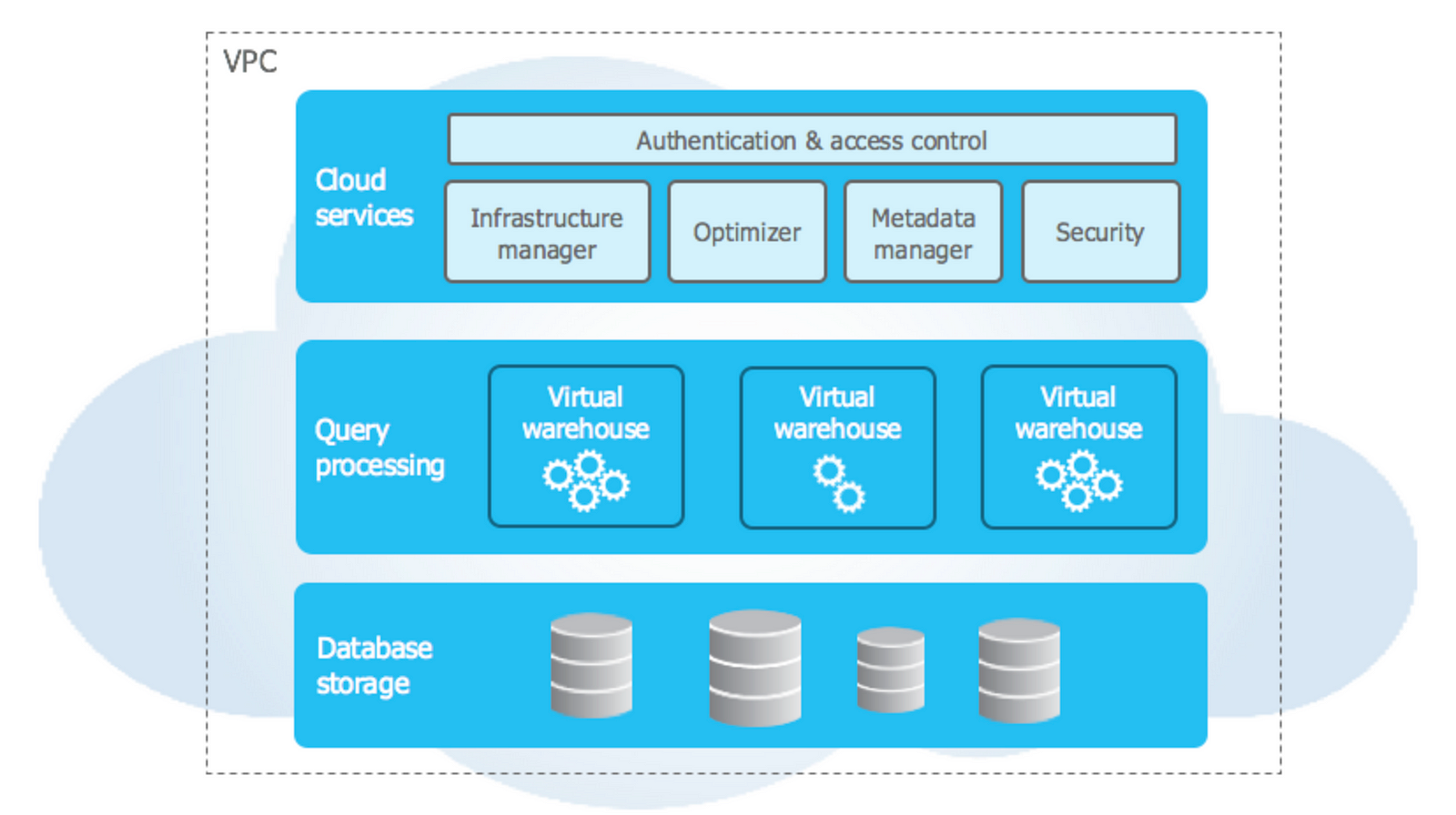
Both platforms store data in native tables in proprietary formats on an internal storage layer.
From a data storage point of view, the main difference is that BigQuery bills the number of bytes stored uncompressed while Snowflake charges the compressed amount. Pricing per TB for both solutions is close to distributed storage pricing. Depending on the data types and data the difference between uncompressed and compressed can add up to a 60–80 % difference.
Google BigQuery charges less for partitions or tables that have not been updated in the last 90 days while the data remains immediately available. Snowflake charges the current storage and any other storage by other features such as time travel and fail-safe. Transient tables can be used to avoid fail-safe storage costs but make sure you have the data available in another service if a reload is required.
Snowflake and BigQuery can access data in distributed storage as external tables. For most workloads, the data storage costs are a small part of the running costs so try to avoid premature optimization.
Snowflake and BigQuery fully separate storage and compute. The way compute is exposed and billed is very different.
On the Snowflake platform, each SQL query runs in a “virtual warehouse”. A virtual warehouse, expressed in a “T-shirt size”, is a cluster with a number of servers. The number of servers in a cluster double for each T-shirt size.
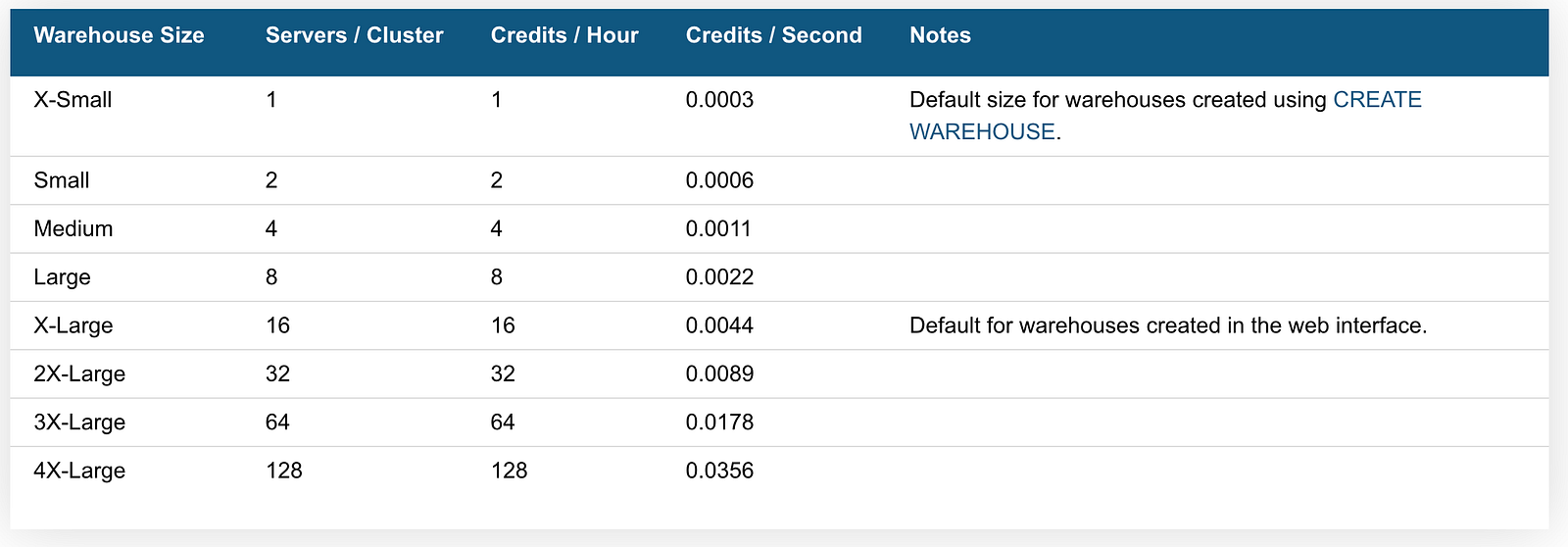
The size of a virtual warehouse has an impact on the number of files that can be processed and query execution performance.
Query performance scales linearly but as in any distributed system, this depends a lot on the data volumes, query operations and the number of partitions you are processing. Snowflake tends to feel a bit faster on small and mid-sized tables with queries that execute in less than a second.
If you want to increase query concurrency, Snowflake can easily scale out by adding a number of extra clusters. Billing is done per second, with a 1-minute minimum.
Virtual warehouses start in milliseconds so it is possible and recommended to use auto-resume and auto-suspend. The number of credits you burn depends on the warehouse size and the time the warehouse has been spun up.
BigQuery with the default on-demand pricing is fully billed based on the number of uncompressed bytes each query processes. The available compute is based on a fair scheduling algorithm. Each GCP project has access, by default, to about 2000 query slots. A slot is an amount of compute/memory available for query processing.
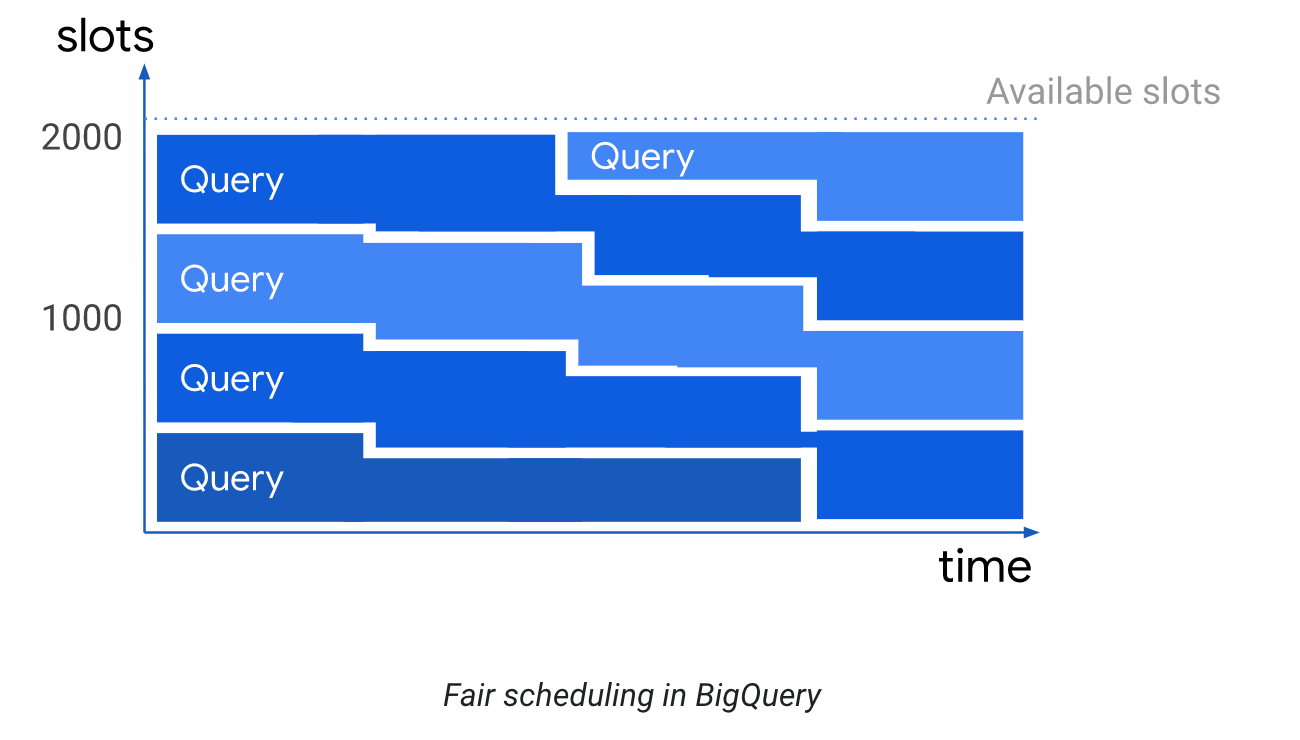
If your BigQuery workloads are too expensive with the on-demand pricing model or you want to have predictable costs, it’s possible to switch to slot-based flat-rate pricing. You can reserve and assign a number of slots to a number of projects permanently or assign flexible slots for a shorter duration, with a minimum of 1 minute. Check the flat-rate pricing for more information.
Snowflake forces you to manually size and assign a virtual warehouse.
This capability is a game-changer in real life because you can easily separate different workloads, for example, a long-running data transformation job versus ad-hoc light dashboard queries, by assigning different warehouse sizes and auto-scaling multi-cluster warehouses for each connection. Warehouses can be started and suspended using SQL so it’s easy to integrate into any data pipeline. Check out our blog post about right-sizing your virtual warehouse size.
In BigQuery you can improve query concurrency by setting separate projects and enable predictable costs and performance by provisioning a specific number of slots to optimize query costs. 2000 slots commitments for each project to achieve on-demand pricing performance and query concurrency can be an issue from a cost point of view.
Running a certain workload in fixed-price mode is possible with flexible slots but I’ve not seen this for operational/management reporting. The current reporting tools don’t support calling the REST API before running a set of SQL queries. This is feasible for batch data pipelines by using a job orchestrator to call the reservation API before/after the query.
Query optimization & caching
The differences in pricing, probably triggered by architecture choices in the storage and query layer, have an impact on the performance optimization features.
Snowflake aims to be as hands-off as possible. In most use-cases, on tables smaller than a few TBs, no manual optimization is required. For large tables, clustering keys can be specified if the default way of working doesn’t match the type of queries. Filters on columns with high cardinality can be optimized using the search optimization service. Auto-reclustering is automatically done in the background.
BigQuery requires a bit more upfront design for large tables. It’s essential to adapt the table partitioning and clustering to the most popular queries to keep the number of bytes that are scanned under control. Additional bytes can be avoided by nesting repeated data. The pitfall is that the majority of the reporting tools, except Looker, don’t support nested data structures and the SQL statements can be complex.
Caching in Snowflake is different from BigQuery.
Queries are cached in the virtual warehouse layer as long as the warehouse is running. Tuning the auto-suspend parameter of the virtual warehouse can improve queries that access similar data. More important is the fact that Snowflake manages the query result cache on the account level. If the underlying data has not been changed, queries can be returned without running a virtual warehouse for up to 24 hours.
In BigQuery caching is done on user level. More advanced caching can be configured using BI Engine.
Data loading and unloading
Both solutions offer similar ways to load data with the main differences that loading data into BigQuery in batch is free. Streaming data ingesting is possible using a REST API out of the box or with the upcoming BigQuery Storage Write API billed at a rate per MB or GB.
In Snowflake data ingestion is not free but plenty of options are available:
- Snowpipe — micro-batching with billing per second instead of virtual warehouse pricing
- COPY — batch data ingesting from internal & external stages that require a virtual warehouse
- Apache Kafka connector
Data unloading in BigQuery is free by using the shared compute pool or $1.1 TB via the BigQuery Storage API.
In Snowflake data unloading is done using the COPY statement so a virtual warehouse is required.
Since the latest Snowflake release support for data formats and automatic schema detection for ORC, Parquet and AVRO are very similar except that BigQuery has no out of the box XML support.
Other costs & cost controls
Next to data storage, virtual warehouses, serverless features such as the use of Snowpipe, Snowflake invoices the use of cloud services, if these exceed 10 % of the daily compute costs and any egress costs (if data travels between regions or cloud providers). A detailed view of the costs is available in the web UI and the account_usage database.
BigQuery invoicing is slightly less complex because optimizations that automatically run in the background, time travel storage, the use of the metadata and other platform costs are not charged. A detailed view of the costs per query and the slot reservations is available in the audit tables and billing exports. The UI, API and command-line tools can estimate the costs of a query before it’s executed.
Both Snowflake and BigQuery offer enough measures, such as resource monitors, to monitor costs and set maximum budgets.
Conclusion
Coming from BigQuery, it’s essential to understand the way virtual warehouses can be used in Snowflake to optimize the costs and performance of different workloads. If the data size and the number of queries is small, this is a bit more work compared to BigQuery in the on-demand pricing model.
In environments with a lot of queries generated by reporting tools, a number of data engineering tasks that run frequently together with less frequent but unplanned data discovery and data preparation workloads for AI, the separation into separate virtual warehouses is a very welcome feature with an immediate impact on user experience and cost management.
Data ingestion in Snowflake is not as real-time and API-driven as BigQuery but enough features, such as Snowpipe, are available to cover most workloads at an affordable cost. At Tropos.io, as a Snowflake partner, we can help your team with designing a cost-efficient, secure and flexible data pipeline.
In the next blog post, I’ll focus on data sharing and multi-cloud capabilities.







